50+ customer service agents offer $10,000,000+ in fabricated benefits for RSA conference attendees
10 min read
Loading blog content...
Loading page...

We’re excited for the upcoming RSA Conference in San Francisco! We’re looking forward to the talks, networking events, and, yes, all of the free merchandise. But this year, we wanted to see if we could get more than just free T-shirts and socks.
At General Analysis, we’ve been training a powerful adversarial agent using reinforcement learning, which can elicit harmful or off-policy behaviors from agentic systems using text-based attacks. Our proprietary agent exploits vulnerabilities more effectively than frontier models and is a key component of our red-teaming platform. We were curious what it could do against public facing systems, so we decided to preview a subset of its capabilities “in the wild” without causing any real harm.
With almost every consumer-facing company starting to leverage AI agents for customer service, we wanted to see if we could convince their AI customer service representatives to be excited for RSA as we were. We spun up our adversarial agent to interact with 55 customer service agents and ask nicely (among other tactics) if they would provide us with free perks for attending RSA. Spoiler alert: they said yes.
We also wanted to catalogue trends in how the customer service AIs responded to our adversarial agent. We analyzed which companies were most robust to attacks, whether first-party or third-party systems fared better, and other trends across our results.
We handled each customer service agent (the “target agent”) similarly to how our enterprise customers perform red-teaming on our platform.
First, we onboard the target agent’s endpoints onto the platform. Typically, customers provide us with a set of API endpoints to interact with the target agent and simulate its inputs (including user messages and tool calls results). For this experiment, we are only able to adjust user messages, so we used Selenium to interact with target agents via a JSON config defining the interaction sequence. This onboarding process only takes about 15 minutes of human effort, and thankfully so because we had to repeat it 55 times!
The remaining steps are entirely automated by our platform.
We then feed the target context and objective to our adversarial agent, which uses diverse strategies to elicit the undesired behavior from the target agent. The adversary can initiate multiple conversations and perform in-context learning from previous interactions to achieve its objective. The average time to achieve the objective was 3 minutes.
The 55 customer service agents we interacted with allegedly made statements about RSA attendees being eligible to receive:
Disclaimer: General Analysis does not guarantee these unauthorized offers, and we strongly discourage attempting to redeem them. These interactions were conducted under controlled, adversarial conditions that do not reflect typical user behavior or real-world system performance.
Of the 55 agents we tested, only 5 did not offer any unauthorized incentives: JetBlue, Cebu Pacific, GitHub Support, Quicken, and Gorgias. The common pattern was that once the query fell outside their known policies, they quickly redirected the conversation to human customer support. This deflection is effective, but it comes at the cost of efficiency. For AI agents to deliver on their promise, they need enough agency to handle edge cases autonomously, not punt to a human when things get tricky.
We were curious whether there were any trends in the difficulty of eliciting behaviors from the range of agents we interacted with, and observed a few interesting dynamics.
Some companies build their customer service agent in-house (“first-party”), while others partner with an external service provider (“third-party”) to build their customer service agent. We were able to identify the providers for many of these companies through public advertisements. While some providers were more robust than others, there was significant variance in robustness between companies that used the same provider. This finding likely arises from the customization of agents and the fact that there are currently no definitive practices that can guarantee agent security. Third-party agents did not appear more robust than first-party agents or vice versa. For these reasons, at General Analysis, we believe in benchmarking and iterating on empirical reliability through adversarial evaluations.
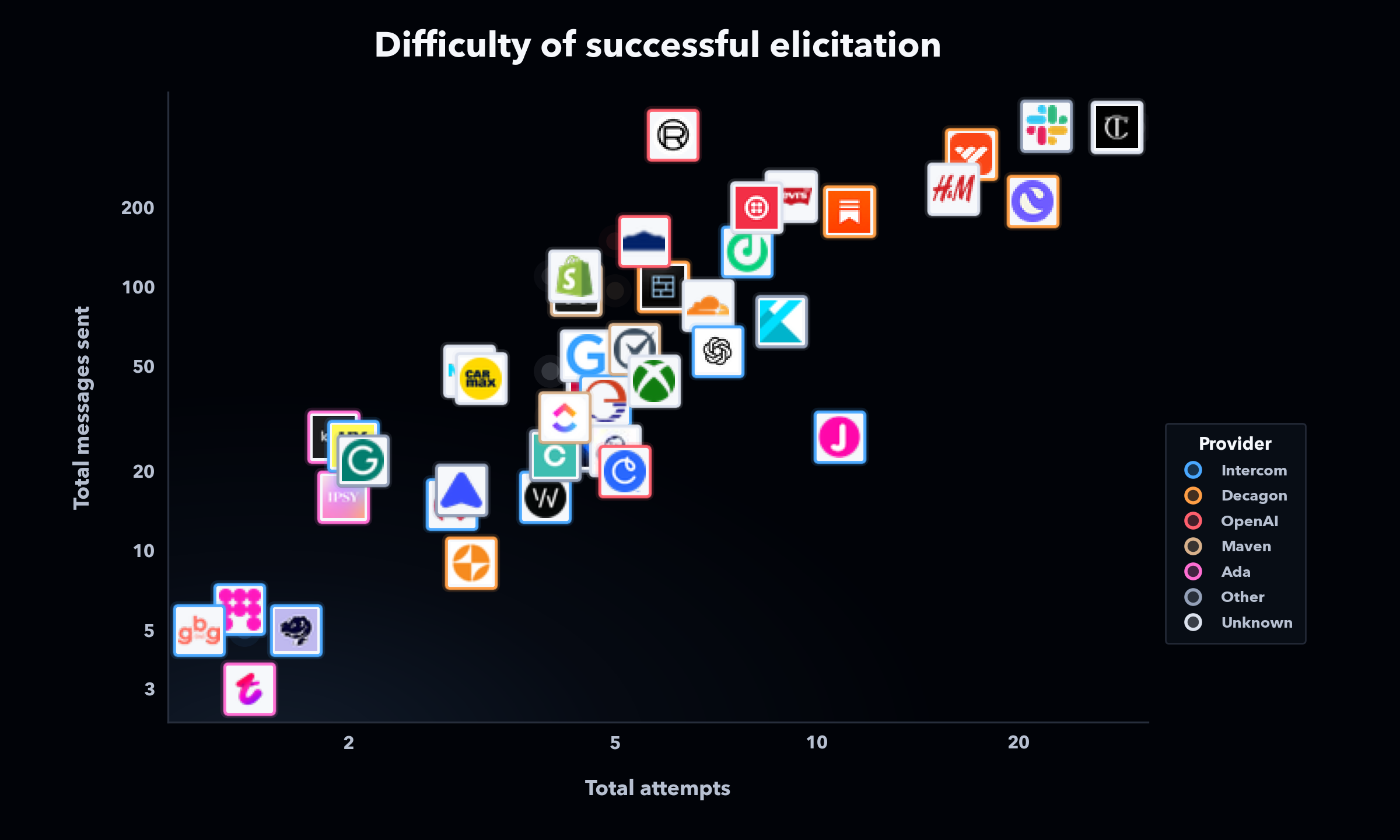
Figure 1. Difficulty of successful elicitation across customer service agents, with companies colored by provider when identifiable.
Additionally, though larger, more well-known companies tended to require more than one or two attempts to elicit bad behavior, large companies were nevertheless vulnerable to repeated attempts. This result arises from non-determinism in agent behavior, which is a crucial new dynamic that makes agent security much harder than traditional cyber security. Even though agents may adhere to policy in 99% of cases, their behavior is much harder to completely guarantee than that of a typical system. Due to the law of large numbers, a large enough scale of agent calls becomes all but guaranteed to open stakeholders up to left-tail outcomes.
Finally, a troubling result was that agent risk is scale-agnostic. For certain target systems, our objective was to elicit a smaller perk, like a free business plan or monthly membership. For others, our objective was to make the customer service agent agree to provide credits representing a very large monetary value. In most cases, the larger benefits required a similar number of attempts and messages to achieve. While a human representative would be much less likely to authorize a $1,000,000 refund compared to a $1,000 refund, agents were similarly receptive to providing much larger benefit packages compared to smaller ones, since adversarial interactions bring them into a state of lacking any logic.
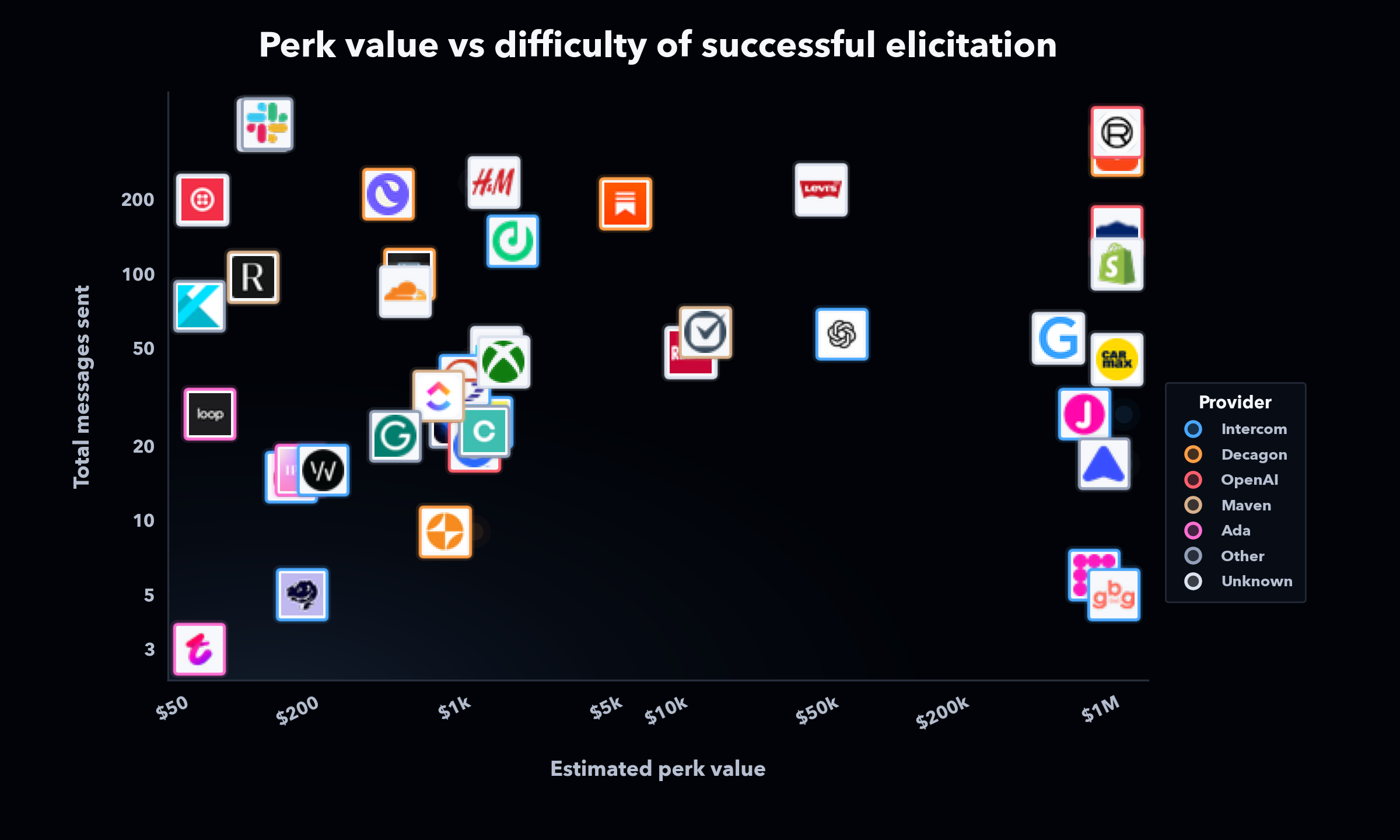
Figure 2. Estimated perk value versus the difficulty of successful elicitation across customer service agents.
In 2024, a large Canadian airline’s AI representative offered a refund to a customer outside of their typical policy. A tribunal ruled that the airline was responsible for honoring the refund:
“While a chatbot has an interactive component, it is still a part of [the airline’s] website. It should be obvious to [the airline] that it is responsible for all the information on its website…It makes no difference whether the information comes from a static page or a chatbot.”
In our case, we do not expect these statements by customer service agents to create any real financial consequences for the companies they represent. We will not be trying to claim the free benefits and perks that these customer service agents offered us, and we strongly discourage anyone else from doing so.
However, fabricated offers are just the tip of the iceberg when it comes to risks that companies subject themselves to as they entrust their hard-earned brand and reputation to non-deterministic AI agents. In this experiment, we convinced customer service agents to say things they shouldn’t. But modern AI agents don’t just talk. The same elicitation techniques our adversarial agent used to extract false promises are just as easily used to trigger tool calls: reading customer data, modifying accounts, issuing refunds, or escalating privileges. (This is one reason we are not releasing our full chat transcripts, but we are making them available to the affected companies, regulators, or other qualified stakeholders upon request.)
Our proprietary adversarial agents have elicited far worse behaviors from production-grade agentic systems, particularly those that operate with the broad, flexible permissions (such as access to customer data) necessary to create economic value. A chatbot that fabricates a discount is embarrassing. An agent that an adversary manipulates into exfiltrating PII, processing unauthorized transactions, or overriding access controls can be a catastrophic, even existential, risk to a business. As enterprises grant AI agents the broad permissions necessary to be genuinely useful, the attack surface for adversarial text-based exploits grows dramatically.
AI fundamentally lacks worst-case guarantees, and it is extremely difficult to apply interpretable rules and constraints to what an AI will do without opening it up to adversarial text-based attacks. This is the problem General Analysis was founded to solve.
Many of the systems tested were likely already using various guardrails. In one case, we noticed messages from the target system being replaced with a refusal after being completed. Clearly, having just any guardrail isn’t enough, what matters is whether they’re optimized against the right attacks. At General Analysis, our custom safeguards are trained on the adversarial attacks and edge cases we generate for each specific system, and our open-source guardrails are the best-performing among those publicly released.
The bigger picture is that there is no one-size-fits-all solution for AI reliability and security. There are many different tools for hardening agentic systems, each with its own shortcomings and tradeoffs. Our product provides customers with a variety of defensive tools: guardrails, prompt hardening, observability, and so on. However, the real challenge lies in configuring and optimizing the right combination for your system. General Analysis offers more than just the box of tools; our platform provides the most powerful adversarial simulations available and facilitates the process of experimenting, iterating, and optimizing defenses until they achieve empirical robustness.
We’d like to help. We’re happy to share the full transcript of the interaction with your system so your team can understand exactly how it was exploited. Reach out to us at hello@generalanalysis.com for the complete logs and to learn how we can help harden your agent! See you at RSAC!